数据结构之B+树
做应用开发的朋友大概这辈子不会遇到B+树这个数据结构,它的应用场景更多是在底层。
所有做技术的人有时候会面临一些困惑,有些技术或者理论离应用太远,有点曲高和寡,导致了我们会对这类技术丧失兴趣. 但B+树有时候就像一个幽灵一样出现在一些技术文章中,引起你的关注.
这篇文章主要是浅谈一下我记忆中的B+树.
- 背景
- 什么是B+树?
- B+树实践
- 拾遗
背景
要了解B+树先得说说B树, 1972年Bayer和mccreight发明了B树,但并没有说明B是什么意思, B可能代表Balance, Bayer或者Boeing,在这里就不深究B的具体含义了. B树首先它是一棵树,然后它是一颗平衡树,所有的结点都能存储数据。
B+树和B树的关系,大体上看就是iPhone6 plus和 iPhone6之间的关系.
注意:不存在B-树,这个“-”其实是个连接符,但会让人误解为是减号,如果出现B-tree其实就是B树.
什么是B+树?
在讨论B+树之前,我们先要讨论一个阶的概念,就好比有些团队是大团队,有些团队是小团队,阶定义了B+树的规模。
满足如下条件的树,是一颗m阶的B+树
- 根结点的数量在 [2, m] - 大Boss的下属数量范围
- 正常结点的子结点数量范围是[2/m, m] - 中层骨干的下属范围
- 一个结点的关键字数量和指针的数量是一致的,一个关键字代表了子结点的极值 - 老板眼里只有核心员工
- 所有叶子结点都在同一层,叶子结点有指针指向兄弟结点 - 真正干活的只有底层,且底层团结一致
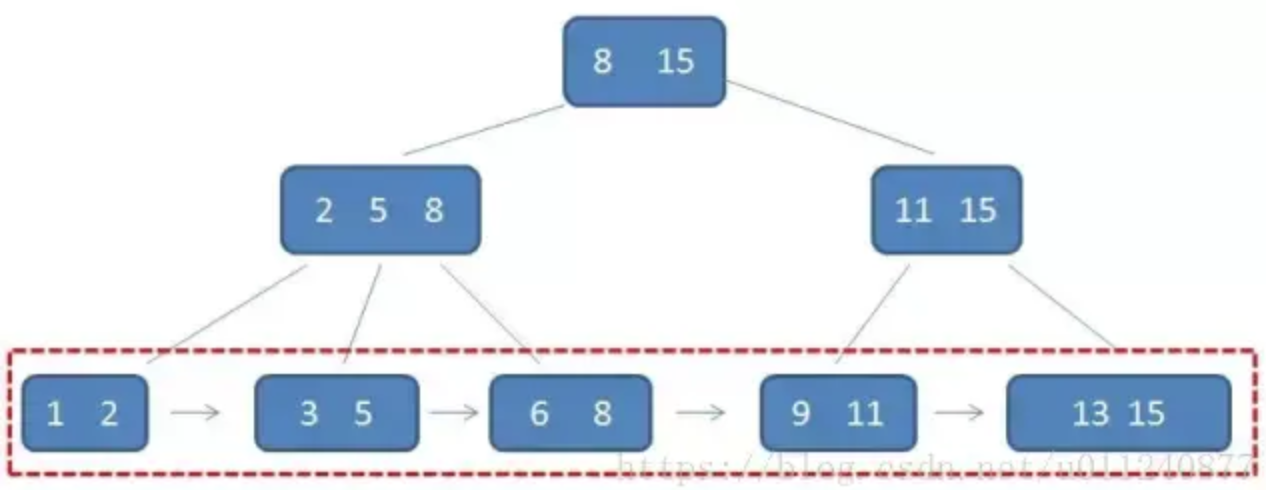
B+树实践
B+树与Mysql存储引擎InnoDB
一些基本事实
- 数据库读取数据是以页(一般而言是4k)为单位将磁盘文件加载到内存(为了方便讨论,一个页上存储一个结点)
- 普通磁盘加载一个页的数据大概需要10ms(旋转,寻道等操作)
- 磁盘的顺序读取I/O比随机读取I/O要快10万个量级
- 内存的读取速度(纳秒级别)和磁盘的顺序读取读取大约是一个量级
- 查询优化的核心是减少I/O的访问次数
为什么不选择B树?
B树的最大特点是是数据分布在所有的结点中,所有在进行范围查找时候,加载多个页的时候,会很耗时B+树的优势
B+树存储数据的特点- 叶子节点存放了行数据
- 所有的叶子结点都在同一层
- 所有的叶子结点可以形成一个双向链表
- 叶子结点所在的页分布在不同的磁盘块上
- 非叶子结点不存储行数据,仅仅为了存储更多的索引键
通过上面的特点,我们可以知道
- B+树相比B树很明显的一个特点是树的高度降低了,这样I/O访问就少了.
- 存储和索引被隔离开来,软件设计的一个原则就是分离关注点
回头再看看上面那个B+树的图,它有点像什么?对,像跳表. 跳表的核心思想是让链表具有二分查找能力.
所以跳表和B+树的源头思想是一致的.
拾遗
- 由于B+树的读写会导致逻辑上相邻的数据实际在物理上相聚很远,LSM树(日志结构合并树)是对B+树的改进