网络协议之万维网摇篮 - Http
凡是与电脑打交道的人,每天必然会用浏览器,只要用了浏览器就需要输入一个网址。这个网址的样子是这样的: “http://”, 没错,它就是这篇文章的主人公。它是如此的熟悉,以致于我们会忽略它的存在.
它的前世今生到底是什么样子?
- 背景
- http发展历史
- 未来
背景
1965年8月24日,Ted Nelson发表在美国计算机协会(ACM)上的论文,用到了词语
“hypertext”. 这里的超文本和我们现在说的超文本内涵是不一样的.
1989年, 当时在 CERN 工作的 Tim Berners-Lee 博士写了一份关于建立一个通过网络传输超文本系统的报告。这个系统起初被命名为 Mesh。 在随后的1990年项目实施期间被更名为万维网(World Wide Web). 它有四个部分组成
- HTML - 一种用来表示超文本的格式
- HTTP - 用来传输超文本的协议
- 网页浏览器 - WorldWideWeb, 显示超文本的软件。可以打开地址,体验一下第一款网络浏览器.
- 服务器 - CERN httpd.
从这里我们可以看到
- HTML是一种文档格式。再看看现在的Html5,这种变化是相当相当的巨大.
- Http不干别的,就是用来显示文档的.
- 第一个网页浏览器
- 第一个web服务器
- 这里没有JS. 换句话说,不能和网页有交互.
- 这里没有CSS. 换句话说,浏览器的内容没有那么美
我们应当记住这个时间点,在这个时间点上出现了好多第一。而且也应该知道,出现这些东西是简单的和朴素的。这个世界是变幻莫测的,有哪几股力量导致了http, html 变成了今天这个样子?
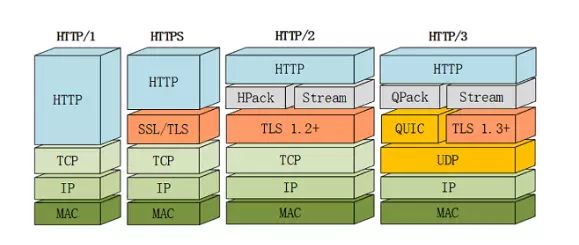
Http发展历史
Http/0.9 - 小学生
Http/0.9在1991年发布。 它是简单的。 它只支持
- get方法。
- 只能返回Html格式的文件.
也没有错误码,如果发送错误,返回一个错误的Html就可以了. Http 0.9真的可以说是技能单一。
Http/1.0 - 中学生
Http/1.0在1996年5月发布,它是http0.9的升级版。 它的能力相比0.9就强多了
- 支持状态码
- 支持多种格式的文档返回类型
- 缓存 - Expires, Pragma
- Keep-alive - 需要显示指定。 默认是短连接
- Http头
- 新的Http方法 - HEAD, POST。 至此,前端开发中最常用的Get, Post方法已经全了
Http/1.0 存在的问题
- 连接无法复用 - 每次通信都是遵循打开连接,接受数据,关闭连接这个过程。这就导致了效率非常低下
Http/1.1 - 大学生
1997年处,Http/1.1发布. Http/1.1的特性在整个Http历史上是革命性的,如同Jquery之于前端, Spring之于Java.
来看看Http/1.1可以做什么
- 持久连接 - 默认支持长连接
- pipelining机制 - 客户端同时按顺序发送多个连接,服务端按顺序返回多个响应
- 新增Http方法 - OPTIONS, PUT, DELETE, TRACE, CONNECT
- Host头 - 支持一个物理机部署多个站点。
- 新的缓存机制 - Cache-control,etag
- 断点续传 - content-range, 隐含了分而治之的思想。
- 分块传输 - transfer-encoding: chunk, 隐含了分而治之的思想。
Http/1.1的问题
- 线头阻塞(Head of line blocking)- HOLB
Http2 - 初入职场
2015年,Http2发布。 Http2与Http/1.1的不同是, Http2在应用层面解决了线头阻塞的问题. 为了解决这个问题,等待了15年.
Http2它有什么能力?
- 多路复用
- 用一个连接进行数据的收发。看到这里有些朋友是不是眼熟?Node和Redis都是用一个线程来专门做特定的事情。 创建一个连接,或者创建一个线程都是有开销的,既然如此,就用最少的连接或者线程好了。
- 一个场景:如果在一个连接上,同时想获取js, css, html文件应该怎么办? 以前的做法是获取完了js文件,然后再获得css文件。一个很自然的想法是将这文件切割和剁碎。然后拿到碎片之后再进行组装,从使用的角度来看,就是并发.
- 流和帧
- 一个流可以理解为一个请求
- 流可以设置优先级
- 流由多个帧组成。 每个帧是标记自己属于哪个流。 就好像每个人知道自己属于哪个组织.
- 帧是基于二进制编码的。
- 在传输过程中,帧和帧是乱序的。
- 基于二进制
- 头部压缩
- 基于HPACK算法
- 在客户端和服务端两端维护各自的字典
- 服务器推送
Http2是否真的完美无缺? 当然不是。 Http2只是部分的解决来队头阻塞的问题. 为什么呢?
因为TCP本质上是要保证顺序的,一个发送的包丢了之后,是无法收到后续发送包的响应的。 所以根据木桶原理,即使上层再怎么拆,怎么分,再怎么捣腾也没有.
一场风暴正在酝酿着.
Http/3 - 职场老油条
既然TCP是队头阻塞的元凶,那么把TCP干了不就可以了?这不可以,因为大多数互联网的设施是基于TCP, 简单的说就是TCP历史包袱较重. 当然了,也不可以对TCP直接修改,这些修改都牵涉到操作系统内核的更新。所以再TCP身上动念头的思路可以停止了.
换一个思路,可不可以从UDP身上下手?让UDP发100个包,它不会多发也不会少发,但它要是包丢了,它也不管. UDP身上的行为比较简单,可以基于 UDP做些事情.
于是, QUIC登场了。 QUIC的初衷是在UDP的基础上,实现和TCP类似的功能,而且要消除TCP的缺点。所以QUIC的整体战略定位还是蛮高的.
QUIC协议支持:
- 建立连接的优化
- 拥塞控制的优化
- 更好的多路复用
- 前向纠错特性
- 连接迁移
这个五个特性的最终目标都是为了一个字:快.
那么Http/3是什么? Http/3是HTTP/2 over QUIC.在2018年10月28日的邮件列表讨论中,互联网工程任务组(IETF) HTTP和QUIC工作组主席Mark Nottingham提出了将HTTP-over-QUIC更名为HTTP/3的正式请求,以“明确地将其标识为HTTP语义的另一个绑定……使人们理解它与QUIC的不同”,并在最终确定并发布草案后,将QUIC工作组继承到HTTP工作组。在随后的几天讨论中,Mark Nottingham的提议得到了IETF成员的接受,他们在2018年11月给出了官方批准,认可HTTP-over-QUIC成为HTTP/3